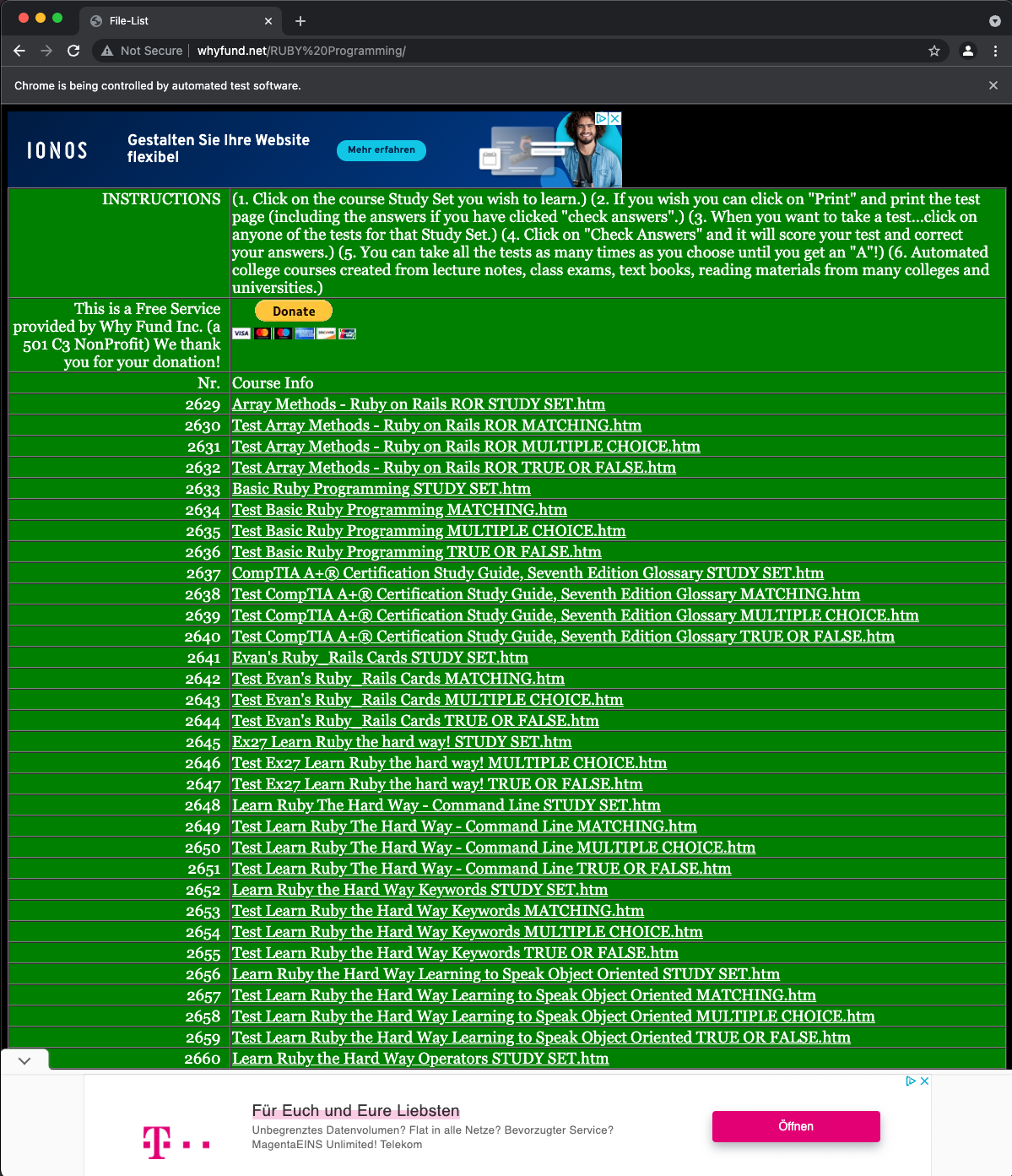
Recently I've stumbled upon an interesting site - http://whyfund.net/. Site contains a lot of studies to master certain skill / language and much more.
As I wanted to refresh my memory around the Ruby language, I decided to give it a try and check how the studies are being structured. I've opened the page that contains ~ 150 sets of questions to master before doing an interview in Ruby.
After looking to a random page with questions and I've noticed that on the bottom of the page there is a Check answers button.
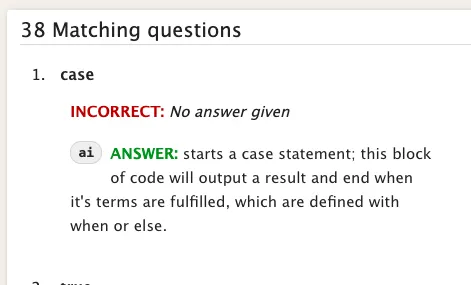
After clicking it, it reveals the answers, which looks like below.
As we have 150 studies, it would be super hard to open each one, click the check answers and download this pages. So then… automation would be a solution.
I decided to build a script using Ruby and popular library that is used for the Web Automation — Watir.
Step 1: Prepare a project
Created a simple Gemfile that contains only watir library
➜ whyfund-get-all git:(master) cat Gemfile
source "https://rubygems.org"
gem 'watir'
running bundle install installed it.
The simple structure looks like
➜ whyfund-get-sets git:(master) ls
Gemfile Gemfile.lock output src
➜ whyfund-get-sets git:(master) tree
.
├── Gemfile
├── Gemfile.lock
├── output
└── src
└── main.rb
The idea is that the output folder will contain the html files and there will be only main.rb file with Ruby script inside.
Step 2: Browser Automation with Watir
Watir is pretty simple and can be easily tested using IRB (which is interactive ruby).
require 'watir'
browser = Watir::Browser.new # opens a Browser window
browser.goto 'http://whyfund.net/RUBY%20Programming/'
puts browser.title # prints title to the console
# => "File-List"
browser.close # closes the Browser window.
As you can see, this opened the Browser (to have browser support go to — https://chromedriver.chromium.org/downloads or use brew install chromedriver on OSX) and load the page.
Here we have a lot of links on this page, so in next step we will collect and store them.
Step 3: Collect all the links
To accomplish this task, needed to use Chrome's Inspector tool to understand where links are placed on the page.
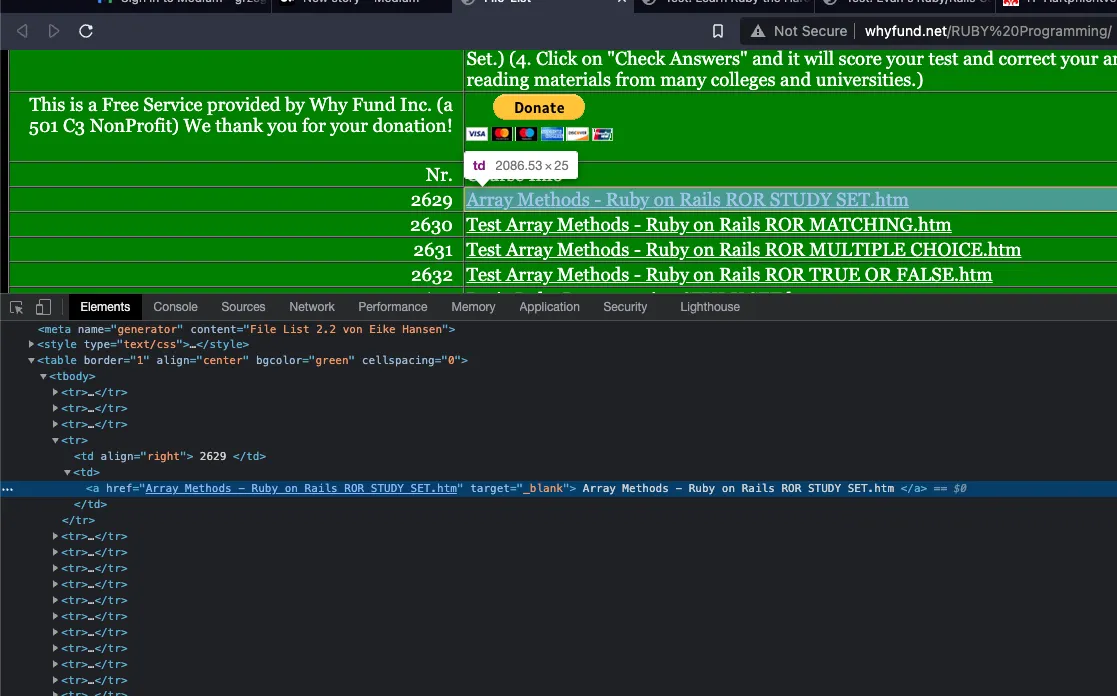
After understanding the HTML layout page, I wrote few lines of code to collect all the links.
def get_all_links(browser)
links = []
tds = browser.tds
tds.each_with_index do |td, i|
begin
p "Checking element #{i+1} / #{tds.length}"
links << td.link.href
rescue
next
end
end
links
end
Turns out that not all the td have a link — and this caused wait delay that is set to 5 seconds by default, and raised an exception. That is why we have a rescue statement and we simply go to next element in the Array.
As 5 seconds, seemed super long, I set the default time out to half of a second.
Watir.default_timeout = 0.5
Step 4: Getting the answers
As we have all the website links in our links variable it was time to open every page one by one and check the answers. For that the below code, almost worked.
def get_site_with_answers(link, browser)
browser.goto link
puts browser.title
buttons = browser.buttons(class: "large button")
buttons.each do |button|
if button.text == "Check answers"
button.click
end
end
browser
end
Why almost? Well, after click on the Check answers I got an exception
=> "http://whyfund.net/RUBY%20Programming/Test%20%20Array%20Methods%20-%20Ruby%20on%20Rails%20ROR%20MATCHING.htm"
irb(main):015:0> browser.buttons[2].click
Traceback (most recent call last):
16: from 15 chromedriver 0x00000001049de754 __gxx_personality_v0 + 253392
...
Selenium::WebDriver::Error::ElementClickInterceptedError (element click intercepted: Element <input tabindex="72" value="Check answers" onclick="return checkAnswers(this)" class="large button" type="button"> is not clickable at point (792, 1221). Other element would receive the click: <iframe id="aswift_2" name="" sandbox="allow-forms allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-top-navigation-by-user-activation" width="1005" height="124" frameborder="0" src="https://googleads.g.doubleclick.net/pagead/html/r20211207/r20110914/zrt_lookup.html?fsb=1#RS-0-&adk=1812271801&client=ca-pub-2916049119845824&fa=1&ifi=3&uci=a!3&btvi=1" marginwidth="0" marginheight="0" vspace="0" hspace="0" allowtransparency="true" scrolling="no" allowfullscreen="true" data-google-container-id="a!3" data-google-query-id="CLmq5v2W-PQCFTHMEQgd-3sOHg" data-load-complete="true" style="display: block; margin: 0px auto;"></iframe>)
(Session info: chrome=96.0.4664.110)
Super long, and super useless to me. After googling, still did not find particular answer, I've noticed that the button it self, was hidden behind an AD!!

Which turns out to be this part of HTML site:
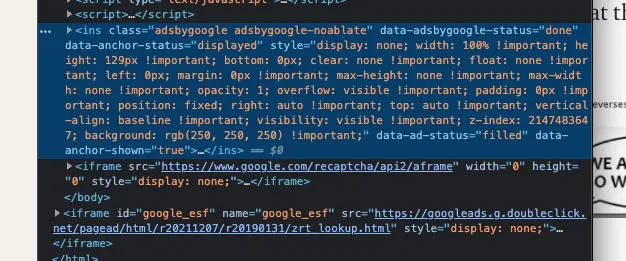
To remove this, I used Watir's capabilities to execute JS:
browser.execute_script("[...document.querySelectorAll('ins')].map(e => {e.parentNode.removeChild(e)})")
The above line of code, removed this <ins> tag and then the click action worked fine.
Step 5: Download the content with answers
In this final step, I wanted to store the page locally. I tried to make a screenshot and save it as image, but it turns out that screenshot is made only for a visible part of the screen, so I would have to scroll down and make other screenshots and then combine them all together — way too complicated.
However, there was a simpler solution, just download the page!
I've created a string that holds the file name. Needed few changes in the name to be more linux friendly. This was done using the gsub method and replaced some characters.
generate_file_name = "output/#{current_site.title.gsub("/", "-").gsub(" | ", "").gsub(" ","_")}-#{Time.now.to_i}.html"
Then, just wrote the HTML to this file.
File.open(generate_file_name, 'w') {|f| f.write current_site.html }
And that was it all.

Conclusion
Having interacting with Watir and Ruby was a great fun and also automated the process a lot. The solution can be find on my github account if you would like to watch in action then head out to youtube.
Thank you!